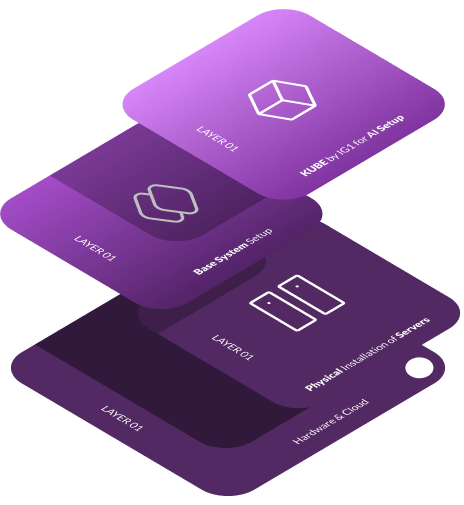
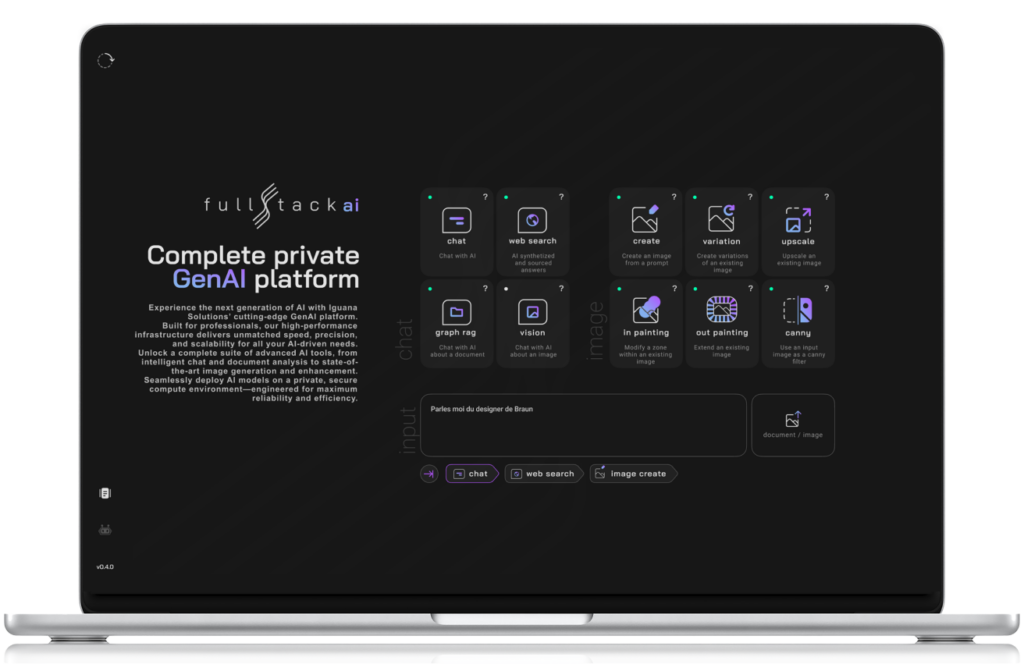
Nous proposons des plateformesGenAI innovantes qui rendent l'infrastructure de l'IA puissante et sans effort. En exploitant la technologie NVIDIA H100 et H200 de NVIDIAde NVIDIA, nos solutions offrent des performances de premier plan pour vos besoins en matière d'IA.
Nos plateformes s'adaptent de manière transparente, passant de petits projets à des applications d'IA étendues, offrant ainsi un hébergement flexible et fiable. De la conception personnalisée au déploiement et à l'assistance continue, nous assurons un fonctionnement sans faille à chaque étape. Dans le monde rapide de l'IA d'aujourd'hui, une infrastructure robuste est essentielle. Chez Iguana Solutions, nous ne nous contentons pas de fournir de la technologie ; nous sommes votre partenaire pour libérer le plein potentiel de vos initiatives en matière d'IA. Découvrez comment nos plateformes GenAI peuvent permettre à votre organisation d'exceller dans le domaine de l'intelligence artificielle, qui évolue rapidement.